For each integration that you add to Stitch, a schema specific to that integration will be created in your data warehouse. The integration’s schema is where all the data Stitch replicates from the data source will be stored.
Integration Schema Names
When you create an integration, you’re asked to provide a name for the integration. This name is used to create the integration’s schema in your data warehouse.
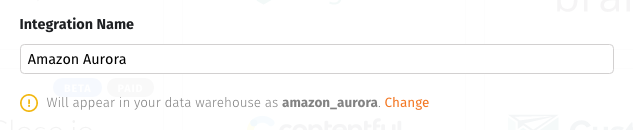
If you want the schema name to be different than the display name, click the Change link below the Integration Name field and enter a new name in the field that displays:

Note that after you save an integration, its schema name can’t be changed.
Changing & Re-using Schema Names
Changing an integration’s schema name requires you to create a new integration and re-sync any replicated data.
Schema names from deleted integrations can be re-used. However, if a naming collision occurs (two schema names canonicalize to the same name) the destination may reject the data - deleting an integration in the Stitch app won’t delete that integration’s schema or data from your data warehouse.
Integration Schema Composition
Schemas created by Stitch contain that integration’s tables and one additional table called _sdc_rejected, which serves as a log for data loading issues.

Aside from _sdc_rejected, the tables that Stitch creates in integration schemas depends on the type of integration.
Database Integration Tables
For database integrations, the schema in your destination will mirror your data source and contain only the tables and columns you set to sync.
There is one exception to this, however: MongoDB integrations don’t support whitelisting at the field level. All fields contained in a collection are automatically set to sync when a collection is selected for replication.
SaaS Integration Tables
For SaaS integrations, the schema depends on whether the integration supports whitelisting:
- If whitelisting is supported, the schema will contain only the tables (and columns, for some integrations) you set to sync. A full list of whitelist-enabled integrations can be found here.
- If whitelisting isn’t supported, all available tables and columns in the integration will be synced to your data warehouse. You can find out more about the available tables and their Replication Methods in the Schema section of the SaaS Integration docs.
Integration Table Schemas
The integration tables in the schema contain the replicated data from tables set to sync. Note that if you unsync a table, doing so won’t remove that table’s data from your data warehouse.
_sdc Columns
In addition to the columns set to sync in these tables, there are also a few columns prepended with _sdc. Stitch uses these columns to replicate your data.
| Column Name | Description |
|---|---|
_sdc_batched_at`
|
Batched desc. |
_sdc_sequence
|
Sequence desc |
_sdc_received_at
|
Received desc |
_sdc_table_version
|
Table version desc |
_sdc_primary_key
|
PK desc |
_sdc_source_key_id
|
source key desc |
_sdc_level_0_id
|
level id desc |
Don’t remove these columns. Doing so will cause replication issues in Stitch.
Data Storage
How your data is stored in the schemas and tables created by Stitch depends on a few things:
- How data is structured in that particular data source (ex: use of nested data structures),
- Any changes you might make to the data source (ex: adding/removing a column),
- Stitch-sepcific data handling rules (ex: entirely
NULLcolumns), and - How your destination handles data (ex: columns with mixed data types, nested data structures)
Stitch will encounter dozens of scenarios when replicating and loading your data. Familiarizing yourself with these scenarios and the nuances of your destination will enable you to better understand your data’s structure and efficiently troubleshoot if issues arise.
To learn more about how handles these scenarios, check out the Data Loading guide for your destination.
Rejected Records Log
Occasionally, Stitch will encounter data that it can’t load into your destination. For example: a table contains more columns than the destination’s supported limit.
On your end, this will usually look like you’re missing data. When Stitch is unable to load data, however, the occurrence will be logged in a table called _sdc_rejected. Every integration schema created by Stitch will include this table as well as the other tables in the integration.
The _sdc_rejected table acts as a log of data rejections and includes the reason, as much of the record that can fit, and the date of the occurrence.
This rejection log can be useful for investigating data discrepancies and troubleshooting errors surfaced during the data loading process.
To learn more about this table, check out the Rejected Records Log guide.
| Related | Troubleshooting |
Questions? Feedback?
Did this article help? If you have questions or feedback, please reach out to us.